Brand Builder AI
A case study in encoded judgment — and what it taught me about the next shape of design work
I built Brand Builder solo, in roughly 4 months starting on evenings and weekends, by encoding fifteen years of brand-strategy judgment into a system of durable, testable artifacts — and then letting the tool run on top of them.
The product is real. Founders complete a three-minute conversation and walk away twenty minutes later with a complete starter brand: positioning, identity, voice, color, type, motion, accessibility, deliverables across the surfaces they'll actually use it on, and a `design.md` that hands off cleanly to any downstream tool. It works. It's specific. It doesn't sound like AI.
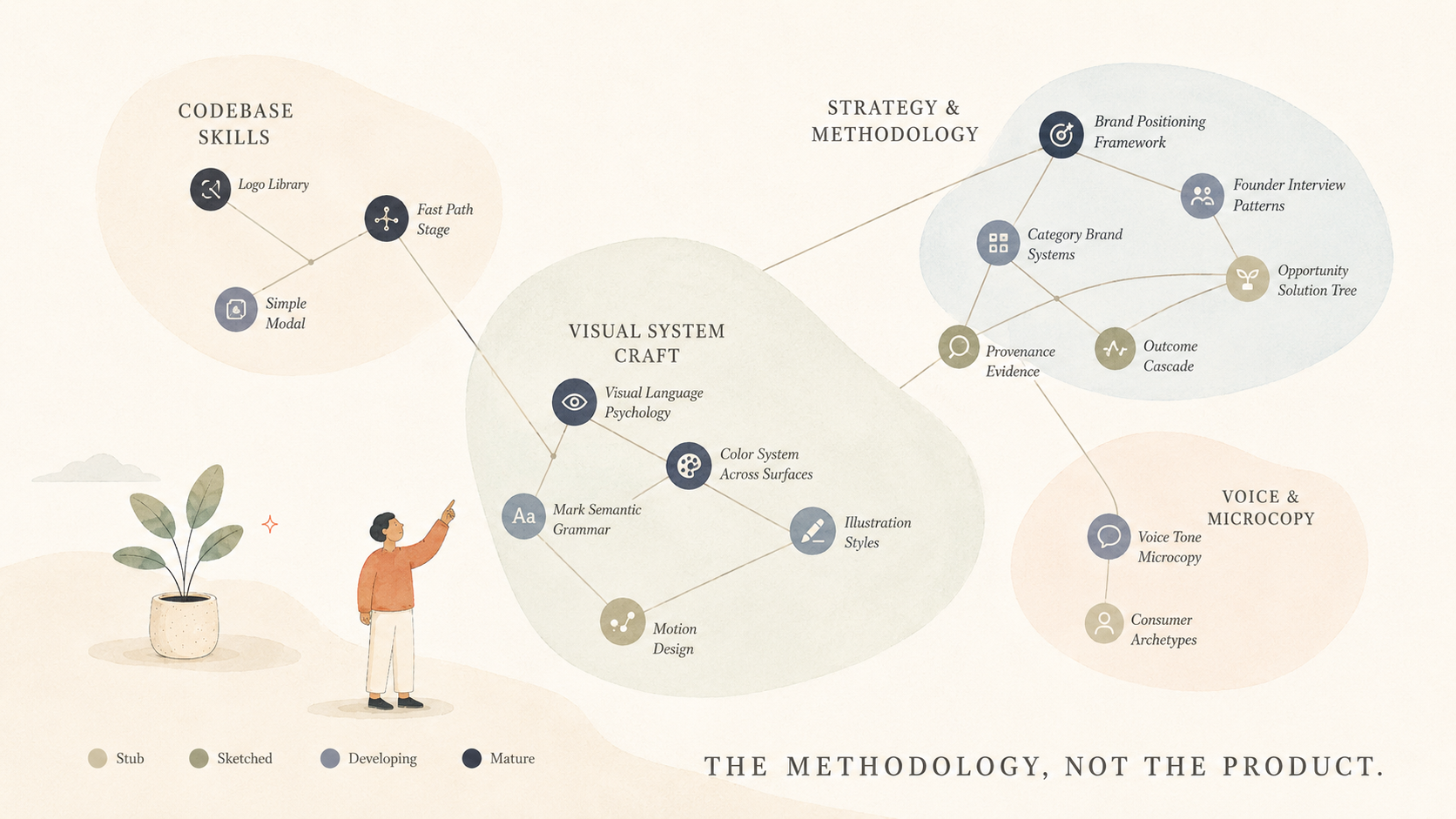
But the product isn't the case study. The case study is the methodology underneath — a skills inventory of about eighteen units, each one a packaged piece of expertise the LLM loads on demand, each one statused and growing. The product is the proof that the methodology compounds. That methodology is the thing I'd hand to a team. The product is just one expression of it.
This case study is about the thinking that produced both. Please join the waitlist of brand-builder.ai, I’d be happy to let you give it a try.
Why a Brand-First Approach
I want to name a tension I've watched for many years.
On one side: founders who need a credible brand foundation to fundraise, hire, and ship — and a market that sells them either a $30K–$80K agency engagement they can't justify pre-seed, or a DIY logo generator that produces something shallow enough they're embarrassed to use it. About 500,000 U.S. founders fall into this gap each year. The work is real, expensive, slow, and structurally unavailable to most of the people who need it.
On the other side: a quiet conviction among design leaders that brand strategy is too taste-driven to systematize — even as the same leaders watch generative AI tools fail to systematize it. Logo generators that produce four geometric primitives in a rotation. Brand-kit tools that pick fonts by category and call it done. Tools that confuse the outputs of brand strategy with the judgment that produced them.
Both sides are right about something. The first is right that the market is broken. The second is right that taste can't be templated.
The way through wasn't a better template. It was a different unit of work entirely.
Skills First APPROACH
A skill, in this system, is a packaged piece of design expertise — strategy, methodology, accumulated craft — that lives as a single markdown file (skill.md) with a sharp description field. The LLM loads it on demand: when a founder asks a category-shaped question, the category-brand-systems skill loads. When the logo synthesis prompt runs, the mark-semantic-grammar skill informs it. When a palette gets pressure-tested against real surfaces, the color-system-across-surfaces skill carries the rules.
Skills compound. Prompts decay. A prompt is a one-time configuration. A skill is the durable form of "here's what I keep re-explaining to junior designers about how to read a color in dark mode." Once you write it down well, the LLM can apply it forever, you can sharpen it across uses, and other people on a team can contribute to it. That's the methodology.
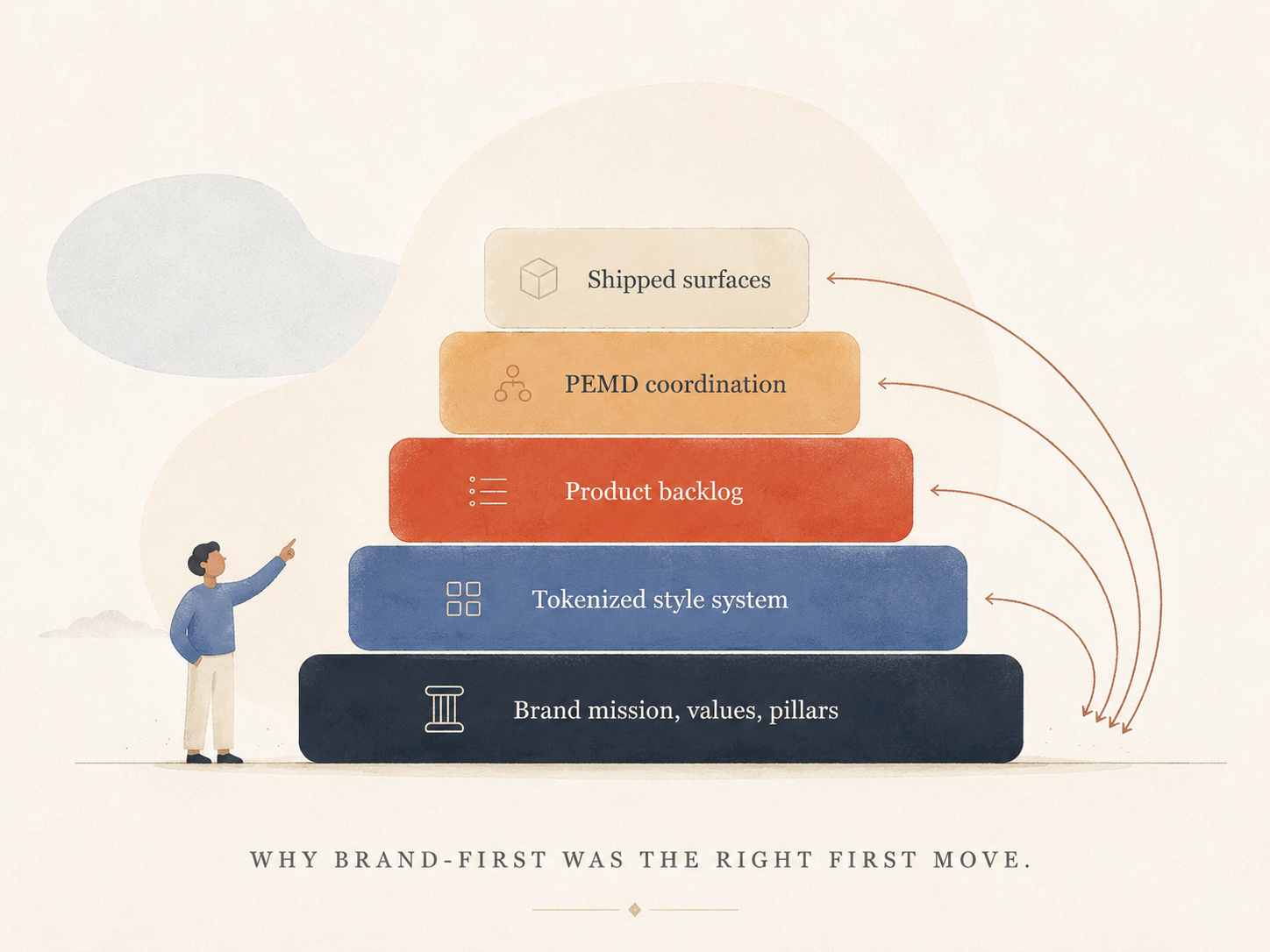
Brand-first was the deliberate sequence. Not because brand is more important than product — but because every downstream decision (which feature to ship next, which audience segment to lean into, what to put on the home page, how to write the empty state) is more when it's rooted in a clear brand mission, values, pillars, and a tokenized style system. Founders who go through Brand Builder end up self-aware about why their product looks and reads the way it does. That self-awareness is the lever the rest of the system is built to amplify. It’s my belief that ‘brand is the felt relationship between the business and it’s audiences, and the product is the truest expression of the brand.
The skills system
Let me get concrete about what's in the inventory, because the abstraction "skills system" doesn't land until you see the shape.
There are codebase skills that protect the prototype from breaking in subtle ways when new features land:
logo-mark-libraryfast-path-stagesimple-modal
There are strategy and methodology skills that carry the thinking:
brand-positioning-frameworkfounder-interview-patternscategory-brand-systems
There are visual craft skills that carry the judgement:
visual-language-psychologycolor-system-across-surfacesmark-semantic-grammarillustration-stylesmotion-design
And there are voice skills that carry how the brand actually sounds:
voice-tone-microcopyconsumer-propensity-archetypes
Each skill has a status — Stub, Sketched, Developing, Mature. I downgrade them when I haven't touched them in months and the prototype hasn't exercised them. The downgrade is a signal that the skill might not be earning its place. The inventory is the source of truth: if a SKILL.md exists in the directory but isn't in the inventory, it's dead to me — either add it or delete it.
I wrote this in the skills inventory and meant it:
“a skill that's never tested against real outputs is just opinion under markdown headers.”
The status labels and the maintenance discipline are how I keep myself honest about which parts of my own taste are working in practice and which are decoration.
A worked example — what one feature looks like
Here's a single feature, end-to-end, that shows the methodology in operation. It's the logo upload flow, the most-used path in the tool.
A founder uploads their existing logo — in whatever format they happen to have. PNG, JPG, SVG, WebP, GIF, TIFF, AVIF — the server normalizes everything to a vision-ready PNG, sanitizes SVG content, rejects HEIC and PDF with friendly conversion guidance, enforces a dimension floor so the read is meaningful. The vision LLM analyzes the mark and returns a structured read: composition, mark type, type stance, corner stance, palette extraction, voice signals, confidence notes, a crop recommendation. That read shows up to the founder as a calm informational panel: *"Here's what we read in your mark."* Composition. Type. Corners. Palette swatches. Voice words. When confidence is low, the panel leads with the system's own uncertainty. When the LLM suggests a tighter crop, a small "Crop & re-read" button appears with an inline cropper that re-runs the analysis on the selection. Below the read, two correction surfaces:
A structured selector
Symbol only / Symbol + brand name / Brand name in type / Something else. Pre-selected from the vision read, but explicit. The founder either accepts our guess by moving on or overrides with one tap. When they pick "Brand name in type," the renderer auto-flips to wordmark-only mode so the tool stops trying to use the typelogo as a square symbol on favicons and app icons.
A free-text textarea. Anything we missed?* Optional. The textarea grows louder when confidence flagged uncertainty. Whatever the founder types is spliced into every downstream generation prompt as an authoritative override — *"the founder's classification wins on conflict."* What's interesting isn't the UI. It's the cascade.
One classification selector and one text area input.
From those, the founder's confirmed type and their own words flow as structured context blocks into five generation prompts — the identity directions, the brand directions, the scene illustrations, the hero image, the deliverable copy. Each consumer of the cascade has its own consumer-specific framing layered on top: scenes care about the mark's corner stance because it dictates illustration line weight; the hero image cares about leaving negative space in the top-left where the mark will sit; the copywriter cares about voice signals because the writing should feel native to the mark. But they all read the same source of truth. One paragraph the founder typed becomes the override layer in five places, in identical shape. When the LLM in the scenes prompt sees *"the founder confirmed this is a typelogo,"* the line weight, palette, and subject choices for the illustrations *change*. When the hero prompt sees the founder's voice override, the synthesized image's mood shifts.
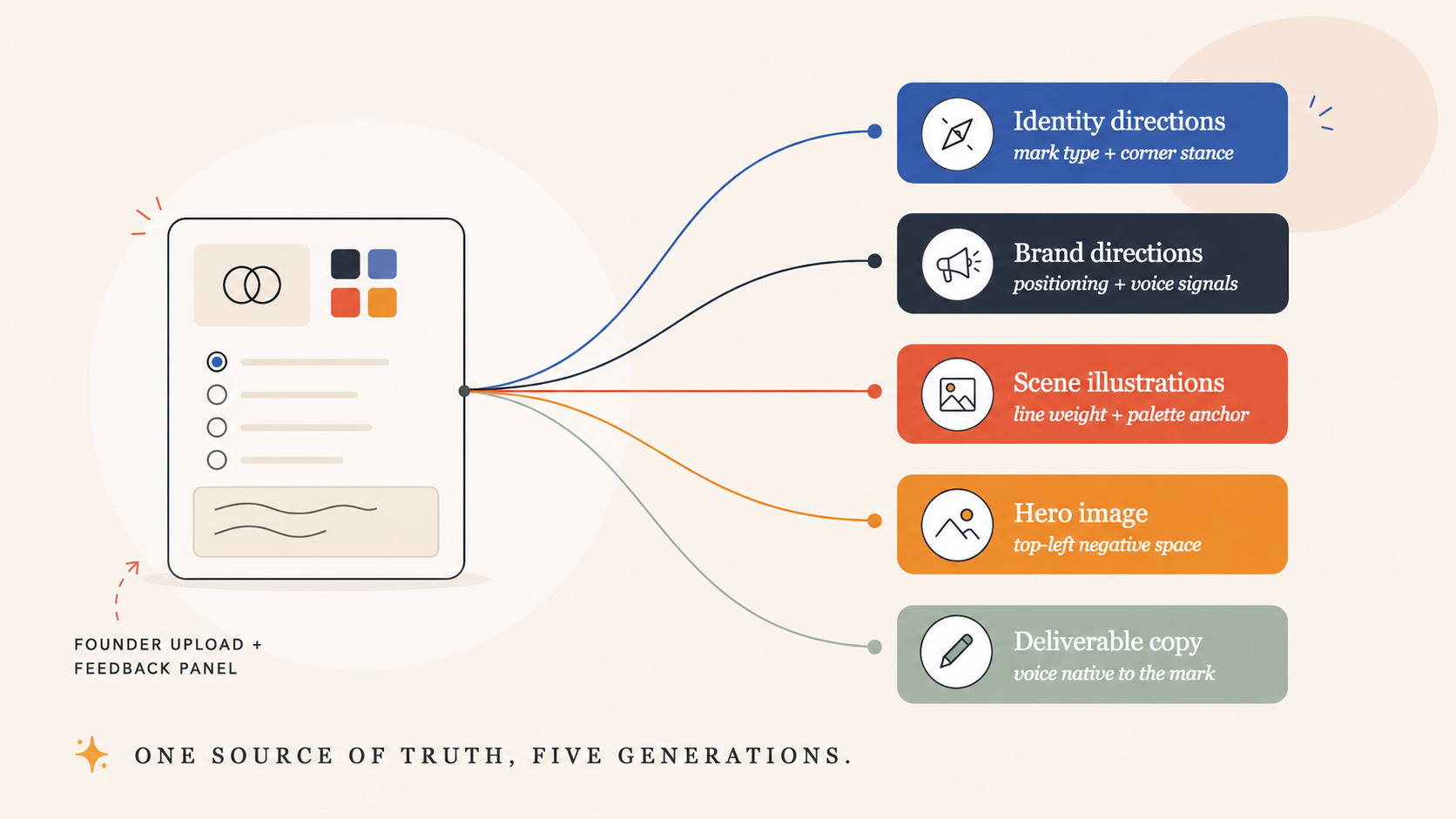
That cascade pattern is the methodology in miniature. The same shape applies everywhere else in the tool: a skill encodes the judgment, the runtime mirror exposes it as a structured context block, every consumer that needs it splices it in identically, and a single source of truth governs the whole surface area. When I sharpen the skill, every consumer gets the improvement for free.
Shipping solo, sustainably
There's a version of this case study where I tell you the stack — Vercel serverless functions, Supabase for state and storage, Anthropic for reasoning, fal.ai for image generation, vanilla web for the frontend — and call it a day. The stack matters, but it isn't the lesson. The lesson is the discipline that made solo-at-scope sustainable.
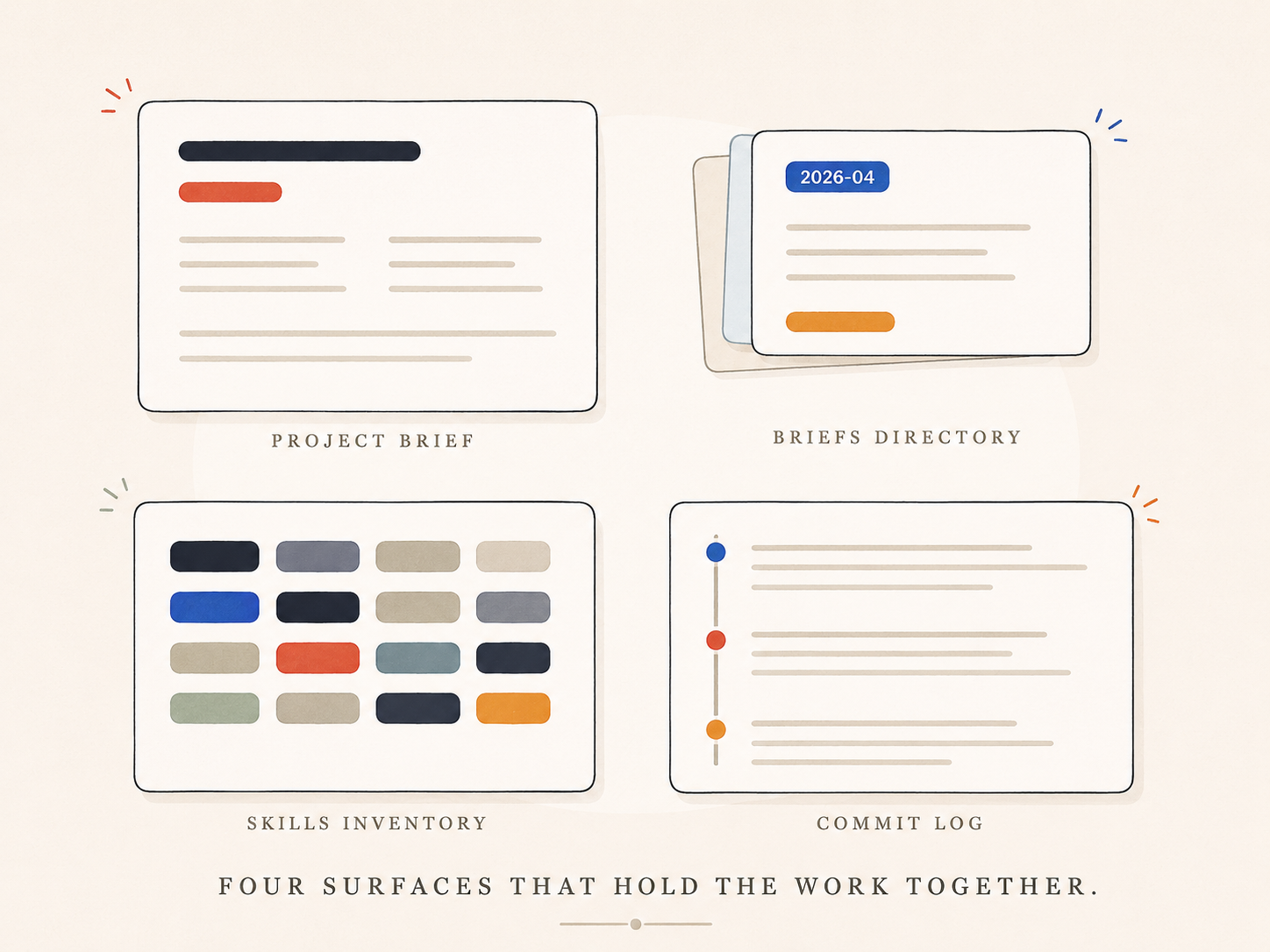
I keep a project brief at the root of the project that I open at the start of every session. It contains the persona (Asha Park — a technical pre-seed founder with strong taste who wants to be *collaborated with*, not generated *at*), the spine (the OST skill), the active tensions, and my house style. Every session inherits it. I don't re-explain the project to Claude every time. I update the brief when something changes.
I keep a `briefs/` directory of design specs, architecture decisions, and worked threads. Each brief carries the date and a structured status. When I want to know why a system is shaped the way it is, the answer is in there. When a future Claude session needs context for a touchy refactor, the answer is in there. The directory is the project's memory.
I keep the skills inventory updated like a real artifact. When a new pattern emerges — when I notice myself re-explaining the same thing in two sessions — I add a row with status `Stub` and start a SKILL.md. Monthly, I walk the inventory and downgrade anything stale, promote anything that's earned it, and process the captures at the bottom.
And I commit with discipline. Every commit message reads like a paragraph from a future blog post. Long-form. Specific. Names the tensions and the trade-offs. When I come back to a system six weeks later, the commit log tells me what I was thinking, not just what I changed.
None of this is glamorous. All of it is what makes the difference between "I built a thing solo" and "I built a thing solo that can grow."
3 Month REtro: What I'd do differently
Three honest reads, in no particular order:
I'd build the skills system first, the prompts second.
I shipped prompt builders before I'd named the skills, then spent months refactoring as patterns emerged. The skills system is what holds the project together; everything else is derived from it. If I were starting again, I'd write the inventory before I wrote the first generation prompt.
I'd frame the ambition as "design builder with brand at the spine" from day one.
I started this as "a brand-foundations tool" and let the larger shape accumulate. Brand-first was the right sequence; the framing wasn't. The product I'm now extending — a PEMD-aware design and product backlog system with brand as its load-bearing layer — is what I should have described in the first paragraph of the first brief. The early positioning made the eventual shape look like a pivot to outside readers. To me, it was always the plan.
I'd write the OST stance as a manifesto for the whole tool, not just as one skill.
The "surface trade-offs, never pick a winner" discipline of the OST should govern every generation surface in the product — the way logos are presented, the way directions are compared, the way the founder is shown the tensions in their own brief. I built the logo-upload cascade first because the founder pain was loudest. If I were sequencing again, I'd write that manifesto first and let every feature inherit from it.
Where it's going — democratizing PEMD backlog work
Brand-first was the foundation. The next layer is what I'm building toward now:
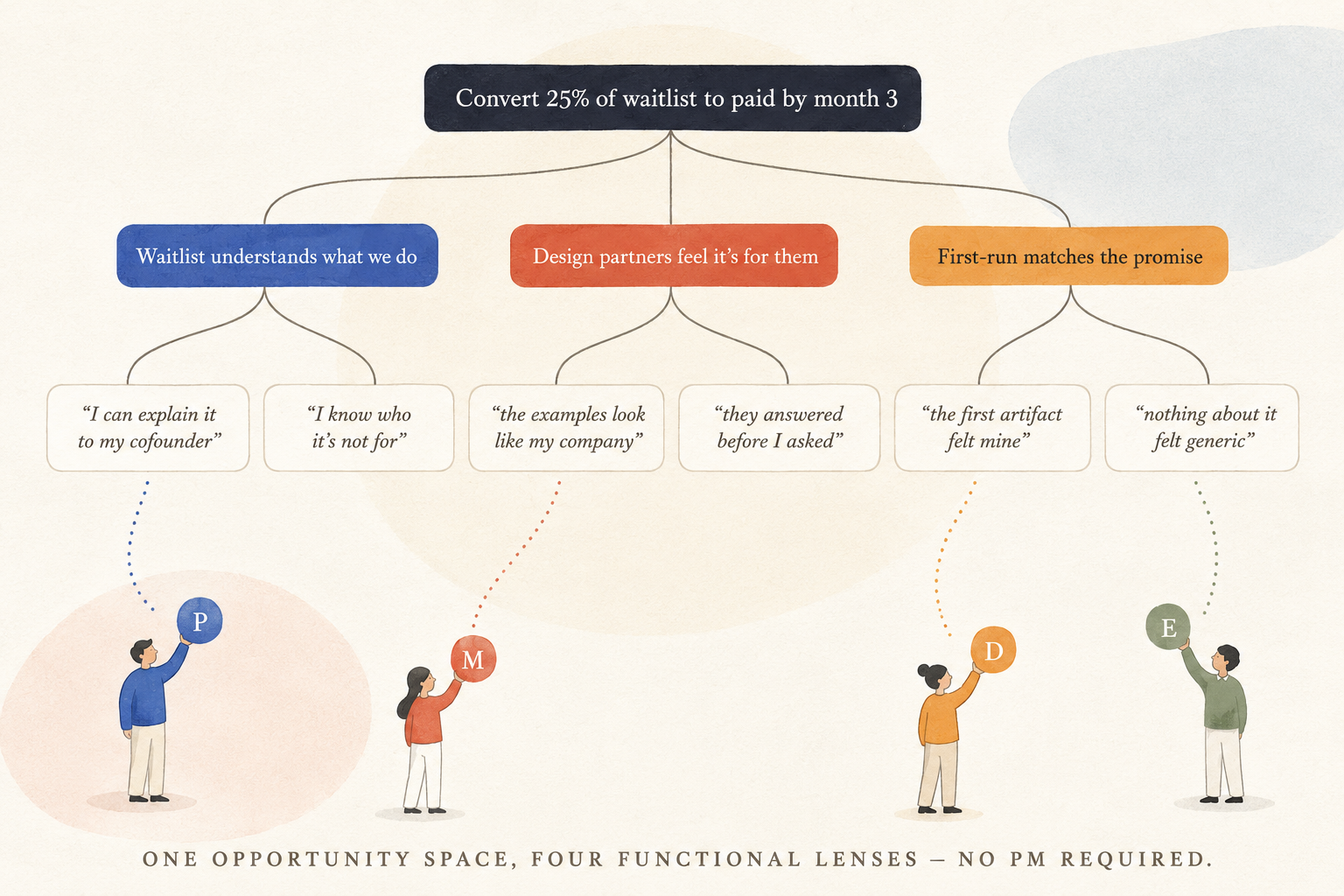
Opportunity Solution Trees (OST)
Turning the same opportunity tree into something four functions (Product, engineering, marketing, design) can co-build a backlog from. — each reading the same evidence, each pulling different work, so bets and investment decisions can be built with shared rationale, but most importantly, shared understanding. For solo founders wearing all four hats, this means simulating four lenses without four people in the room.
The OST skill is the spine of that layer. It generates a Teresa Torres opportunity tree rooted in a real business outcome, with an outcome cascade underneath — because you can't act on a lagging business metric inside a discovery cycle. Brand work doesn't move revenue directly; it moves message-market resonance, recall, trust, intent-to-try. Those move revenue. The cascade makes that line of sight visible.
Every opportunity node carries provenance (`interview` / `brief` / `hypothesis` / `doc`) and evidence strength. The loudest source must not impersonate the truest one. A founder hypothesis is an *assumption to test*, not a finding. Provenance tags survive all the way to the output, so a confident-sounding bet that was actually just optimism reads correctly.
And the discipline that defines the whole stance: the skill surfaces a trade-off comparison and names the tensions — it never emits a score, a ranking, or a recommended winner. The team decides. A skill that picks for the founder is the skill that taught them nothing.
There's a tension here I'm sitting with rather than resolving. The OST refuses to score; TheyDo's (the journey-management platform I'm evaluating for integration) core move is a weighted score. Where does each belong? Is the OST the "make the trade-off legible *before* anyone scores" layer that feeds a TheyDo-style scoring engine — or do these philosophies actually fight? The integration question — does Brand Builder's OST *feed* TheyDo, sit *alongside* it, or *wrap* it — is the next strategic call to make.
Underneath all of it is the wicked problem I keep coming back to: making hard product trade-offs that demand financial predictability AND pure innovation instinct *simultaneously*. The OST is the closest thing I've found to a tool that holds both without collapsing one into the other. It's going to take weeks of build work to make it really useful — and unique enough in the market to matter. I think it's worth the months.
The new wellspring
I want to close on a belief — not a prediction, a belief — that's been shaping how I think about the next decade of design work.
The tools that extract and encode expertise don't replace expertise. They extend its reach. When a brand-strategy decision that used to take a senior designer four hours can be made by a junior team member in twenty minutes — because the methodology that produced the four-hour version has been encoded into a skill the tool runs on — the senior designer doesn't lose their job. The work they do *shifts*. They stop being the person who answers a thousand instances of the same question. They start being the person who *writes* the skill that answers a thousand instances of the same question. Then they go work on the next question.
This is the new wellspring. It's where the next generation of senior design work lives — encoding judgment as durable artifacts, curating systems of those artifacts, teaching teams to read and contribute to them. The design leaders who thrive in the next ten years won't be the ones who watched their teams' work and approved it. They'll be the ones who built the systems their teams' work runs on.
Brand Builder is one expression of that bet. Aether.AI and a handful of other tools in this space are others. The pattern is the same: take the tacit, taste-driven, expensive judgment that lives in senior heads, and encode it as a system that compounds. The product is downstream. The methodology is the asset.
I built this one solo to prove I could. I'd build the next one with a team, because the methodology gets sharper when more people contribute to it. If you're building something where this shape of thinking would be useful, I'd love to connect.